|
I am a Masters in Computer Vision student at the Robotics Institute, part of the School of Computer Science at Carnegie Mellon University advised by Prof. Kris Kitani. My research at CMU is focused on developing computer vision algorithms for Mixed Reality, specifically developing a visual-odometry algorithm for improving state estimation accuracy in Meta's Aria glasses. This summer, I interned at Apple, as a part of the Vision Products Group. I primarily developed a Video Anonymization Framework using generative model based data replacement techniques such as object removal using GAN based inpainting and face anonymization using conditional GANs. I am a teaching assistant for Prof. Jun-Yan Zhu for the course 16-824: Visual Learning and Recognition. Prior to joining CMU I worked as a Senior Machine Learning Engineer at Samsung Research. I have a BTech in CSE from IIT Dhanbad. |

|
|
|
|
|
|
|
|
|
Rutika Moharir , Dishani Lahiri [poster] [code] Developing a multimodal fusion transformer-based architecture for visual-inertial odometry using inputs from IMU sensors combined with sparse camera images to improve state estimation accuracy. |
|
|
|
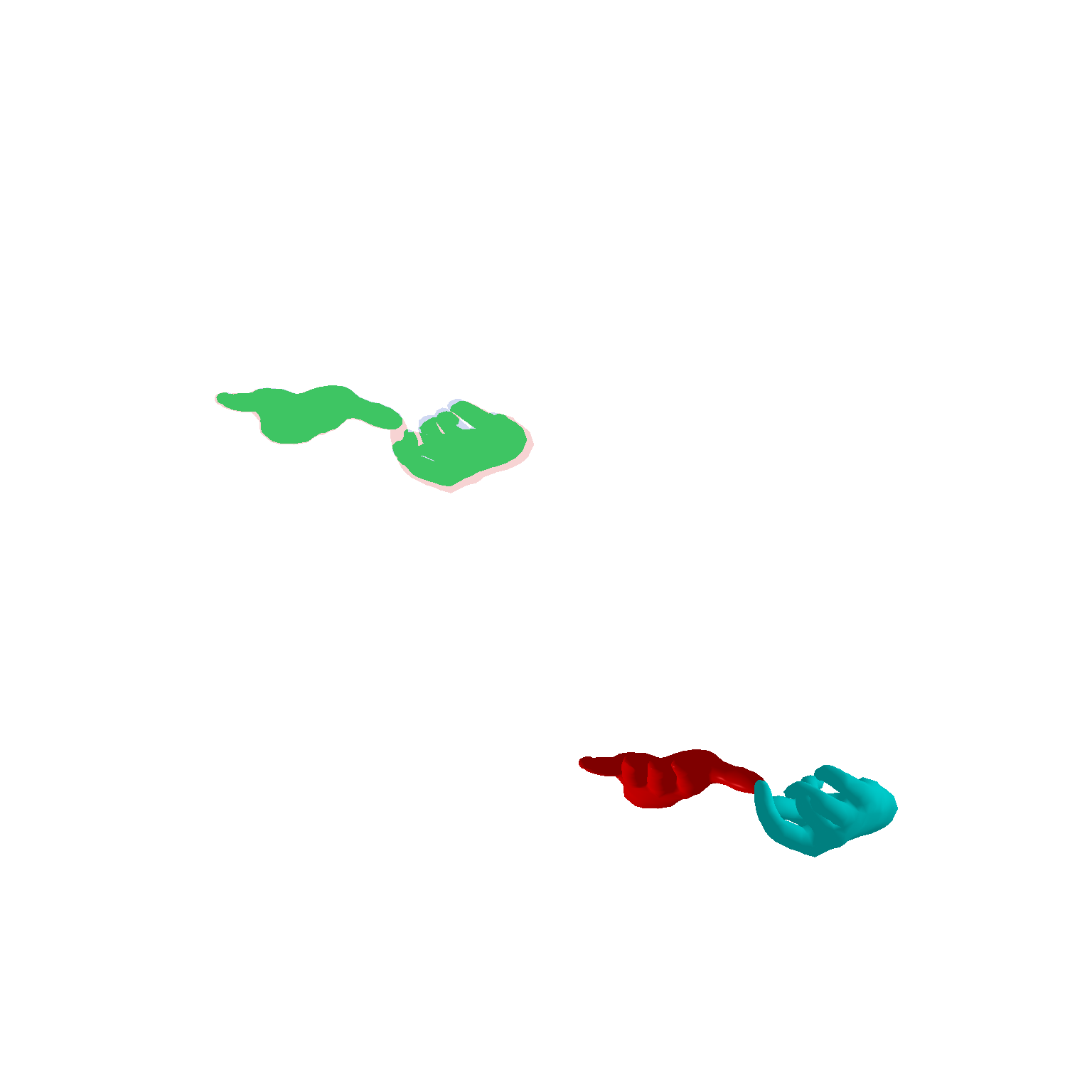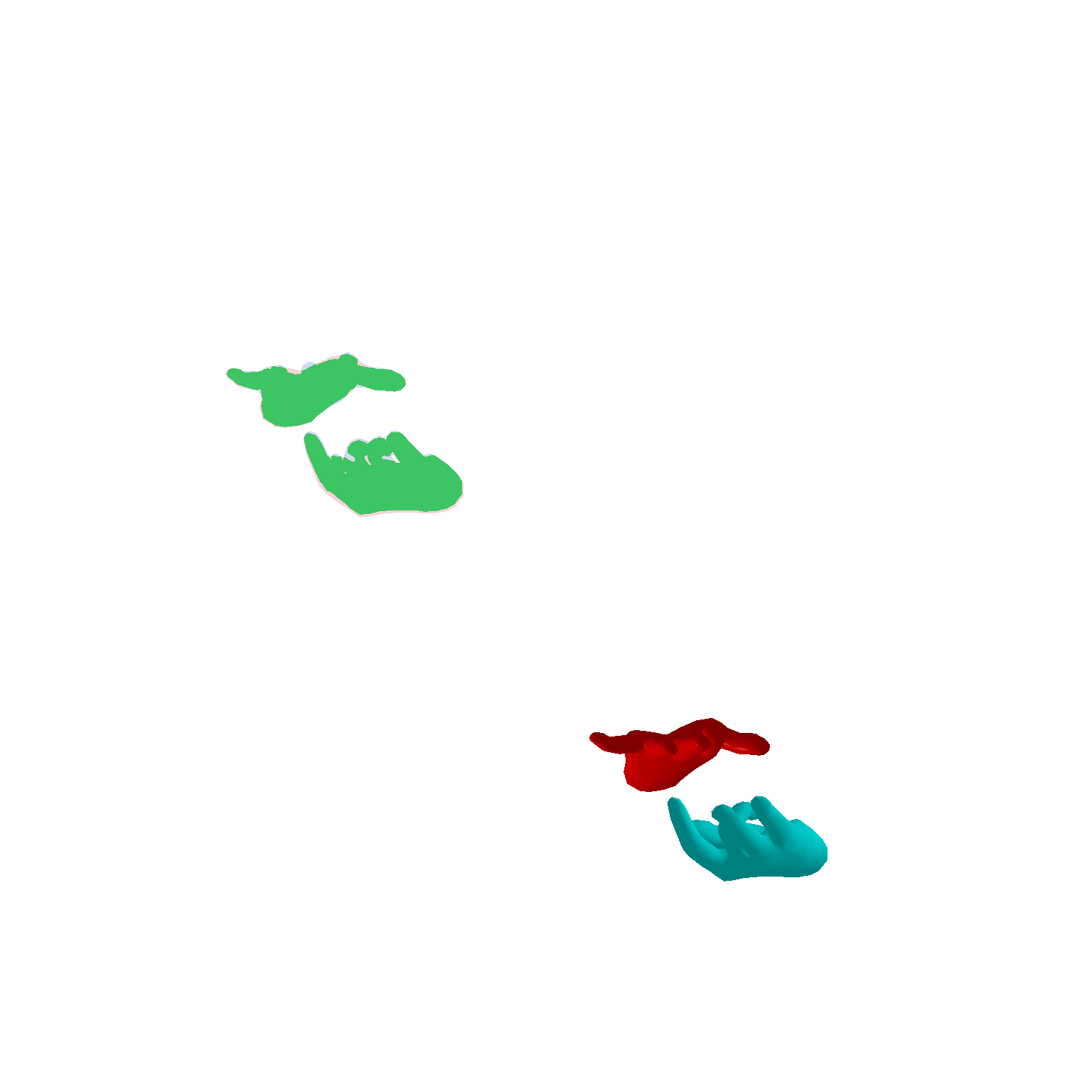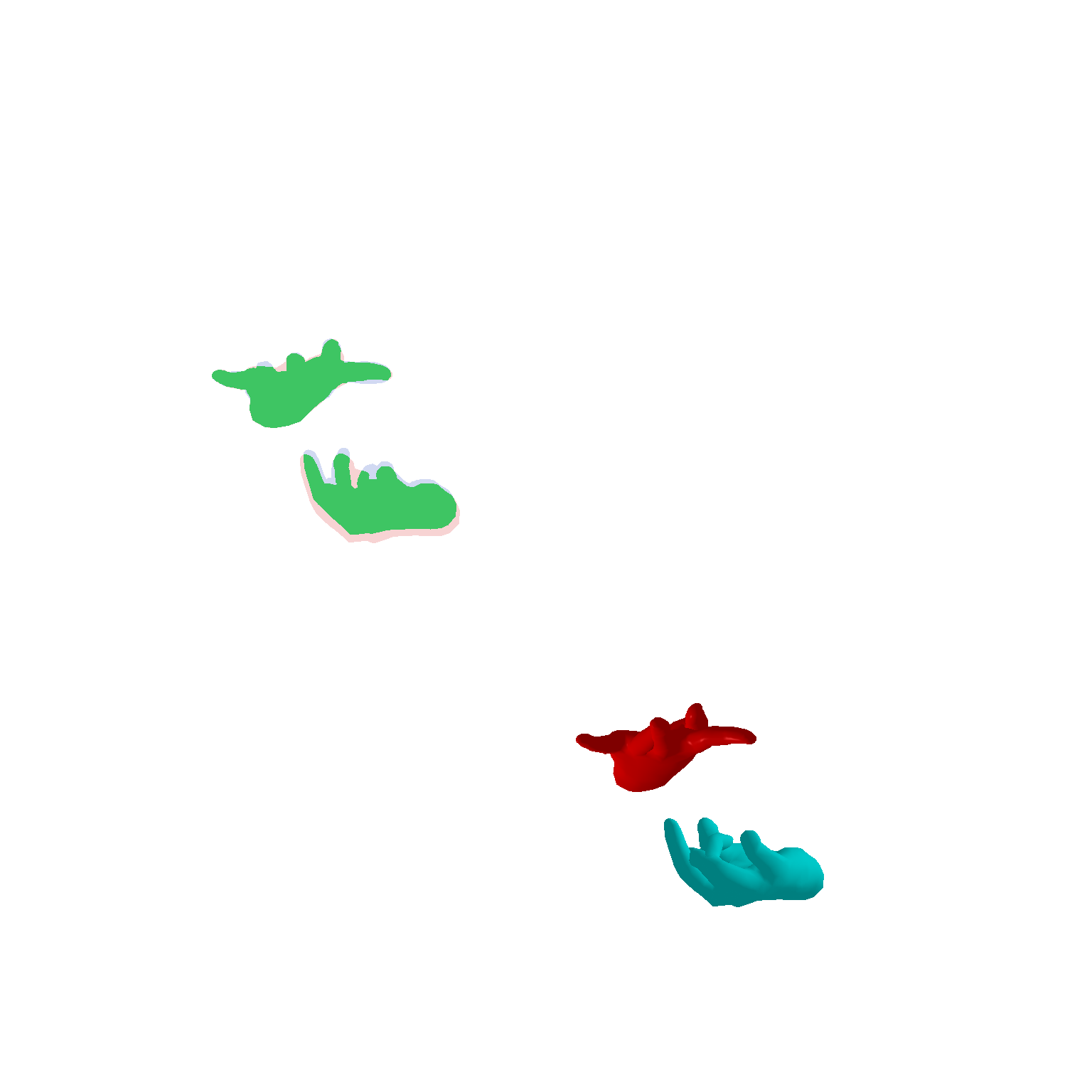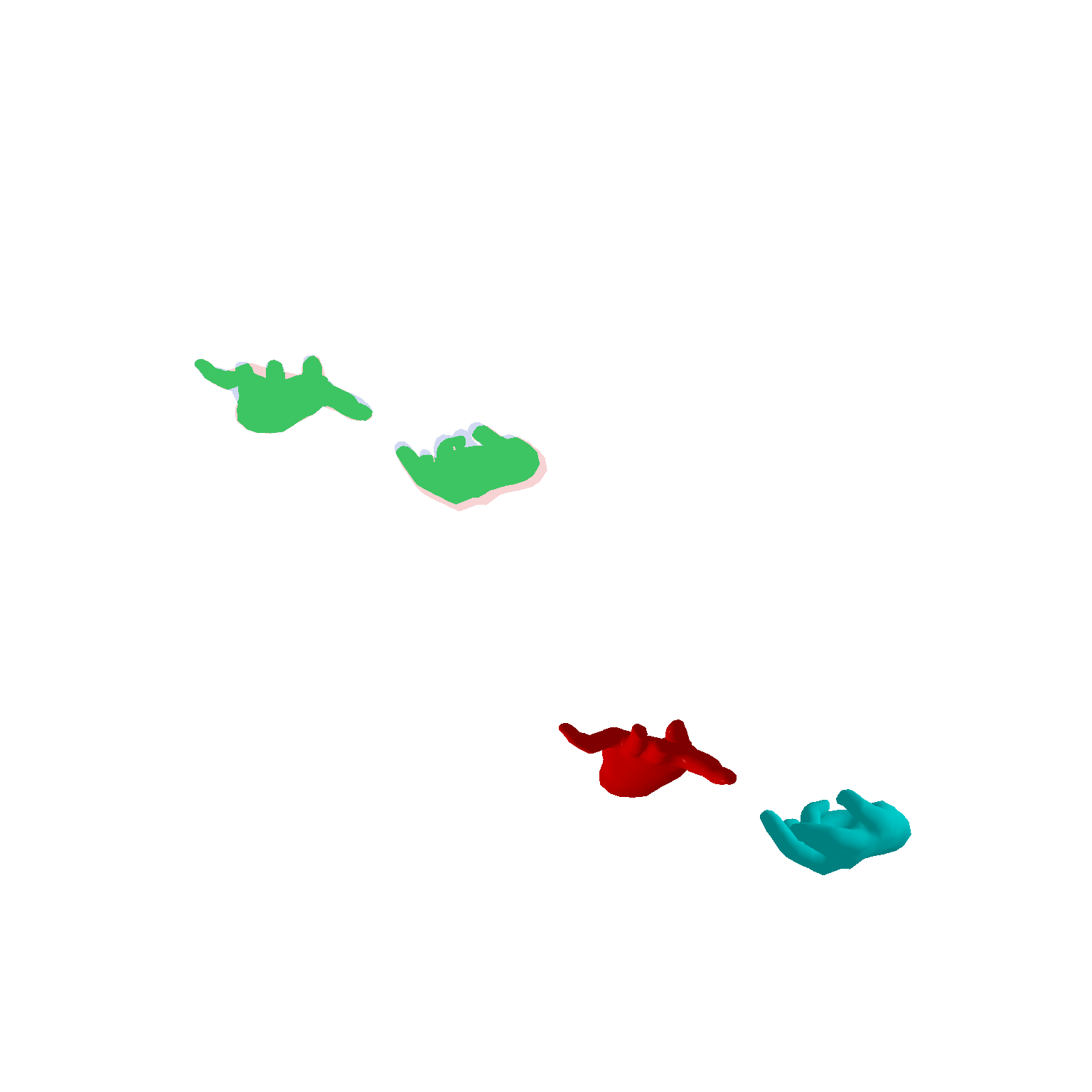
[poster] [presentation] [pdf] [code] Developed a ResNet based network to regress MANO model parameters for 3D two hand pose estimation from a single shadow puppet image.Used optimization to model sequence of hand pose transformations from rest pose to the final pose. Additionally, implemented geometric based losses to regularize the hand pose estimation model.monocular depth estimation. |

|
[pdf] [YouTube] [code] In this work, we explore PPO, DQN, and CEM and compare these methods with the performance of a random agent for solving the problem of music composition. We limit our problem space by only considering two octaves of notes on a single track of composition, for a fixed length. The reward function is hand-crafted from a set of common music theory rules. |
|
|
|
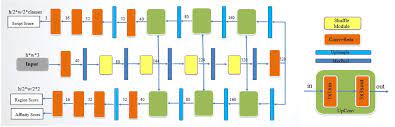
2021 International Joint Conference on Neural Networks (IJCNN) Shenzhen, China, 2021 [pdf] We propose a multi-task dual branch lightweight CNN network that performs real-time on device Text Localization and High-level Script Clustering simultaneously. We also introduce a novel structural similarity based channel pruning mechanism to build an efficient network with only 1.15M parameters. |
|
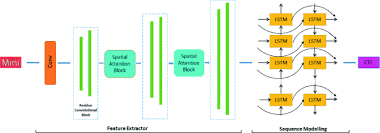
6th IAPR International Conference on Computer Vision & Image Processing, 2021 [pdf] We propose a CNN, equipped with a spatial attention module which helps reduce the spatial distortions present in natural images which in turn allows the feature extractor to generate rich image representations while ignoring the deformities. The CNN learns the text feature representation by identifying each character as belonging to a particular script and the long term spatial dependencies within the text are captured using the sequence learning capabilities of the LSTM layers. |
|
|
|
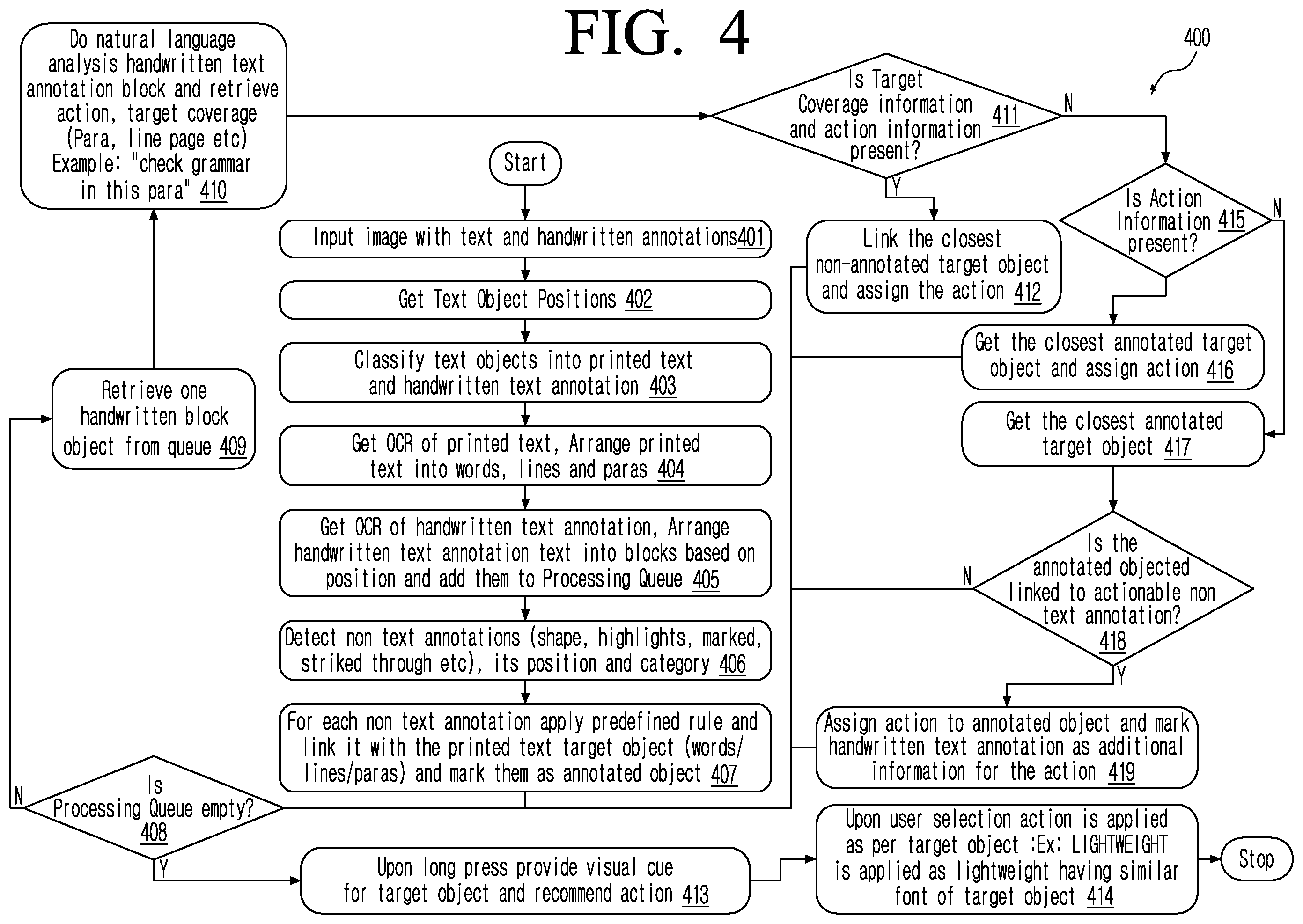
(US Patent App. 17/859,629) [pdf] A method for performing on-device image to text conversion which includes image language detection, understanding the text and using contextual and localized lexicon set for post optical character recognition (OCR) correction. |
|
|
|
[May 2023] I joined the Vision Products Group at Apple as a summer intern. [Dec 2022] I started working as a Research Collaborator under the guidance of Prof. Kris Kitani. [Aug 2022] I began my Masters in Computer Vision (MSCV) at the Robotics Institute, Carnegie Mellon University (CMU). [June 2019] I joined Samsung Research Institute Bangalore-India as a Machine Leanrning Engineer. [May 2019] I graduated from IIT Dhanbad, India with a B.Tech in Computer Science. |
|
Source code from here.
|